Trillian is a data access and computing engine that will enable streamlined and simultaneous comparison of user-supplied astrophysical models against multi-wavelength data from a wide range of astronomical surveys. The project is currently in its early development phases and will grow in power and scope over the next several years. Both interested astronomers and developers are encouraged to join and contribute.
There’s an awful lot of it, which is fantastic. It’s truly amazing, really, the breadth and depth of astronomical data that is available. And more than any other scientific field, our data is open. But the volume has created real problems:
- There’s far too much data to put on your own computer. The full catalogs of WISE, SDSS, 2MASS, Spitzer, GALEX, etc. are far too large to fit on your computer, and most likely your department’s servers as well. The effort of performing large-scale, multi-wavelength analyses falls between difficult and impossible.
- The data is too complex to manage. Even if you had the data releases of all of the catalogs above, they appear in highly disparate forms: FITS files which are all structured differently, gigabytes of plain text files, images, etc. Data is found spread across different HDUs or within FITS headers. Pulling this data together to form a coherent whole that can be easily accessed is a tremendous bookkeeping task that requires skills that astronomers aren’t typically trained in (not to mention the time!).
- More data becomes available all the time. Sometimes a data release supersedes a prior one. Sometimes more of the sky is available. Incorporating and updating new data would be a full time job in itself.
- Astronomical data is closely tied to the details of the instrument. Which flags indicate bad data? Is this instrument sensitive enough to detect the star or galaxy I’m interested in? What is the resolution, and how would I compare it to another data set?
- Web forms are so 1999. Many surveys or instruments provide web forms where you can enter an RA/Dec position (or a short list of them), and retrieve the matched files. This doesn’t scale when you need to analyze thousands or millions of objects, or want to perform an analysis on an all-sky basis.
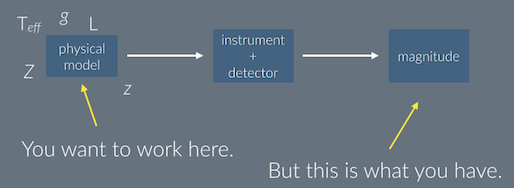
- Most data releases don’t deal in physical units. This is the difference between your model and an observation. You are given magnitudes, but you work in physical units: luminosity, temperature, distance, etc. If you are able to provide a model, the conversion of the observations of several different instruments back to you model requires specialized knowledge that differs from one telescope to another. There’s no reason that every astronomer should duplicate this effort.
All of the above can be distilled into two problems: 1) data bookkeeping and access, and 2) the gap between a physical, astronomical model and a list of observations. The former is a solved problem in computer science circles (just not applied to our data in a modern, scalable way). Trillian aims to address this, but let’s set that aside for the moment as an implementation detail. As an astronomer, you are interested in a physical model.
Let’s consider SDSS as a template. Starting with ugriz images, the Photo software pipeline performs source detection. For each source, three model profiles are applied: a point spread function to detect stars, and two galaxy profiles: a pure exponential disk and a deVaucouleurs profile, each convolved with the PSF. Sources are identified as galaxies or stars, and this binary assignment persists to the final released catalog.
The models are fit based on the five ugriz wavebands, but of course there is more information available from other surveys. Rather than identify a source as “galaxy with a deVaucouleurs profile”, more data can be used to match the model and produce a likelihood. And of course there is much more information available to say much more about stars than “fits a point spread function” (e.g. luminosity, stellar type, etc.). This is not to criticize the SDSS pipeline; its function is not to perform All The Analyses with All The Data. The survey initially only had 16ms to calculate each fit! The problem is that astronomers still use these fits and classifications years later without question when the pieces to create a more complete picture are readily available. And this is true of many other data sets.
Trillian will enable you to apply your own models against hundreds of terabytes of publicly available data, all without downloading a single file. As an example, let’s say I am interested in finding thermally pulsating AGB stars (TP-AGB) everywhere in the sky. I can’t say “these are stars that have a magnitude of x” – that alone doesn’t make sense. As an astronomer, I describe their observable properties in terms of physical parameters: a luminosity range, a temperature range, surrounded by dust, variable, etc. This is my model. To search for objects that match the model, I would need to know how these stars look in SDSS, or 2MASS, or Spitzer, etc. This is a translation from one domain to another that depends on specialized knowledge of each instrument. However, it’s a known problem with a known solution. Very few astronomers have the expertise to solve this problem for each instrument out there, but there is little need to; it can be encoded once into a computation engine.
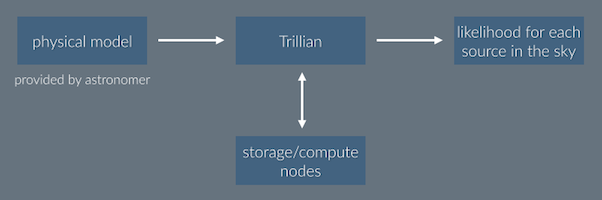
This is the central idea of Trillian: define your model in terms of physical parameters, hand it to Trillian, and the result will be a likelihood value for each object available. What would your model look like as observed by SDSS? By 2MASS? Your model may depend on other existing models (a given Galaxy dust map, a model that identifies stars versus galaxies, etc.). Look for objects that fit a spectrum generated from theory or use a custom stellar population synthesis code to study galaxy histories. All of this is done using as much data is available for each object, a detail that you don’t have to worry about.
A condition of using Trillian is that when a scientific paper is published based on results produced by the engine, the full source of the model will be made available. Scientific results must be reproducible. As with telescope time, users will have a proprietary period before models and their results are made public. Further, as the library of models are built up the resulting database would be a catalog of the sky, identifying quasars, AGN, stellar clusters... everything we have models for. One would be able to ask questions like “Where are all F stars in the sky (above a given likelihood)?” As new data is added, models can be immediately recalculated, resulting in new likelihood values. One could see where the likelihood for the model fit changed dramatically with new data, or remained the same.
When a large number of models become available, Trillian will be able to invert the question and be able to ask the most interesting question of all, the one that we can’t ask today: What data in the sky doesn’t fit any of our models?
Please see arXiv:1402.5932 for a more detailed description of the Trillian platform.