Trillian will require not only the latest developments in computer science and grid computing,
but also presents new and interesting challenges in working with the specifics of astronomical data.
We are actively soliciting development help from the programmer community at large to build a platform
for scientific research unlike any before it. These contributions will enable new and exciting
scientific discoveries.
How can you help? We’re starting from scratch here: we have many terabytes of data from ground based
telescopes (e.g. SDSS,
2MASS) and satellites (e.g.
WISE, Spitzer),
and we are building a new system to distribute it across many nodes. The primary purpose is to create
a computational engine to run user-provided code against the entire data set (or subsets of).
Below is a list of tasks that you can contribute to. Contributions can come in many forms,
from advice to code relating to:
- Data API design.
- Security considerations.
- Managing data distribution.
- Data visualization of terabytes of data.
- Deploying compute instances to cloud services.
- Expert advice on new infrastructure
design/implementation.
- Code!!
High Level Project Overview
While astronomers have accumulated large amounts of data, access to it is highly disparate and not nearly as
easy as it needs to be. This makes all-sky, multi-wavelength analyses extremely difficult or impossible. For example,
let’s say I’m interested in thermally pulsating asymptotic giant branch stars, a kind of star in a specific
phase of its life. No catalog exists of these kinds of stars — they are rare and difficult to find (and even
define). But they can surely be found in the many large-scale surveys
that exist. The stars have certain characteristics: they are very bright, they are variable, they are surrounded
by dust (which means they will be bright in certain wavelengths and dark in others), etc. If I can describe these
characteristics (i.e. a model) as a piece of code, I want to be able to run that “test” against all detected objects
in the sky. For each one, the result will be a likelihood measurement of how well the model fits the data. The system
will understand the peculiarities of each telescope that made the measurement.
Models can be made not only for stars, but dust, clusters, galaxies... really anything that can be found in space.
We will encourage astronomers to build a large number of models. In fact, this is what scientists do— we want to
translate these models into a computational space and apply them to large volumes of data. Once we have a library
of models, then we can ask the most interesting question, the one that can’t be asked today: what, in all of
our observations, doesn’t fit any of our models? It’s here where new discoveries are waiting to be made.
This is how we’ve envisioned the structure, but everything is open to suggestion or comment.
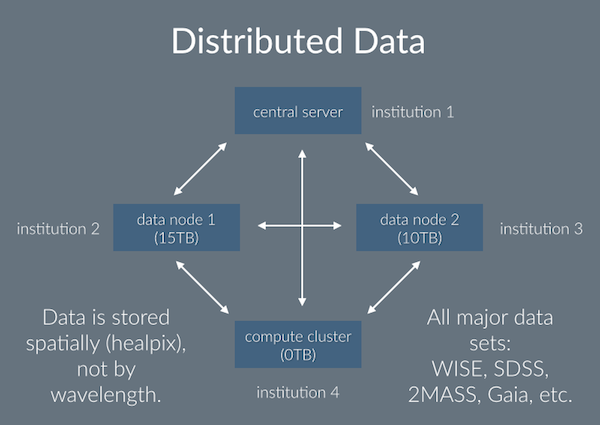
Central Server
A central server will run a PostgreSQL database. This will keep track of what data is available
and where it is. In addition, it will also host several “point source” catalogs. (These are catalogs that
contain a list of parameters for each object detected by a particular telescope; this data is tabular
in form.) Since these are comparatively
small (most are a few GB or smaller), it will be useful to have them all in one place. The database will
also record the results of analyses— another reason to have point source information to cross reference against.
Computation jobs will be farmed out by the central server.
Data Nodes
There is far too much data to store in any single central server, and more is being made available all the time.
We will use Healpix (a system that divides a sphere
into equal-area pixels) to divide the sky. Each pixel will contain all of the data available for that part of the
sky. Some will be tabular (e.g. a list of objects and their properties), some will be more complex (e.g. image data,
spectral data). When a new data node (which may be local or remote) is registered with the central server as being
available, the server will calculate how many pixels of data will fit there, assemble them, and place them on the
node.
Computation Node
Models are submitted to the central server as pieces of code (for now, limited to Python). For each model,
the aim is to compute the likelihood that each object in the data matches the model. For the moment, we will limit
this to a trivial calculation, e.g. is the magnitude (brightness in the sky), between values
x1 and x2)? The computation may take place on the central server or be farmed
out to another node.
Data API
An API is needed to retrieve the data for a particular object or location on the sky. The data may be located
on the central node, but more likely will be located on a remote node. The remote data node may be able to perform
the calculation (in which case the data will not need to be retrieved, only the result), but the data node may
not possess (or grant) the ability to perform model computations. Since an API is required to transmit the data
from the node to the server performing the computation, there is no reason not to make this API directly available
to the public. This will be a very useful tool alone for the astronomical community, which we get (nearly)
“for free”.